If it looks like a words, then it is a word (?)
Being born as a native English speaker is a great luck these days. For the simplicity of its grammar and a predominance in the cultural world from the twentieth century onwards, English, or more precisely one of its dialect is the de facto international language, and being able to speak it natively is a huge advantage. If you are like me, instead, no matter how expert you may become, your level of comprehension of the subtleties will always be lower than that of any native speaker, you will always retain at least a bit of your original accent; you’ll never be able to pronounce all the words in the correct way, and there always will be some word you won’t know.
Among these, the biggest issue with English is its inconsistent pronunciation. Since even native speakers in the same country cannot reach an agreement on how to pronounce a word [1], you may get away with mistakes by claiming that your weird pronounce is actually used by some native English dialect [2].
Something you cannot get away with, though, is the lexicon. English has a huge lexicon. Similar to ancient Romans, English conquered and assimilated, not only people and land but words [[^3]]. I jokingly stated that in English almost any sequence of three letters that look like a word is actually a word. Is this just a joke or is there some truth behind?
One could look into a dictionary to find out, patiently looking for all three-letter words. This is a fair strategy, but dictionaries are a static standardization of a living language, not dissimilar to what a picture is to a person. In particular, dictionary curators are aware that the actual number of English words is much higher than the few hundred of thousand listed in the most thorough dictionaries. Moreover, dictionaries only list one word for each “version”, for example for verbs.
Luckily, Google took a much finer snapshot of the living person that is the English language, by recording all the words in many books from the sixteen century onwards. Google collected millions of books, with billions of pages and about one trillion of unique English word occurrences, in the setting they were actually used. There are downsides here too: mainly the mistakes by the OCR software converting the pictures to the text; also, this is still not accounting for all the words in the language: think about all the colloquial terms, the jargon, that people often use speaking with their friends or colleagues, but that will never be written down, and definitely not in a book!
Building the frequency table
So, let’s play with the Google corpus. The first thing to notice is that it is very large. The list of words in American English starting with “a” takes about 1.5 GB uncompressed. But we are interested only in three letters words and in recent books (let’s say from 1980 onward) so we can download and filter these files at the same time with bash and a simple python script (sadly grep and python2 are easily confused with unicode characters):
for x in {a..z} other
do
wget -O - http://storage.googleapis.com/books/ngrams/books/googlebooks-eng-us-all-1gram-20120701-$x.gz \
| gunzip -c \
| python3 filter.py \
>> three_letters_words_en_us.txt
donewhere filter.py is shown in this GitHub gist.
The resulting file weights just 17 MB, much more manageable. Another short Python script (count.py in the same gist) takes care of grouping the words and computing the frequency (based on the total number of scanned words, that we extrapolated from the total_count file in the Google Ngram website).
The results
The resulting words for six languages are listed in the first sheet of this Google Sheet in decreasing order. All frequency values are shown as base ten logarithms, so a value of -1 means that that word (not differentiate between upper- or lowercase) was used once every ten words, -2 means every one hundred, and so on. The data is rearranged in the second sheet to show for each language how many words pass a certain frequency threshold, and in the third sheet there is a comparison with all possible trigrams.
The first thing to notice is that this corpus is not perfect: due to misattributions and mixed language books, you can find the among the top Italian words, and several other errors.
Also, due to mistakes in the recognition and to the size of the corpus, there are a lot of occasional “words” used only a handful of times. For this reason, I clipped the results to show only words that are more frequent than one in one million words (that is, that have a log probability greater than -6). Still, at the bottom there is a lot of garbage. The correct way to read the table and the graphs is then to decide a minimum frequency, above which we consider those “words of the language”. By manual inspection, the values in which the transition happens is between -4.5 and -5.0.
Number of words
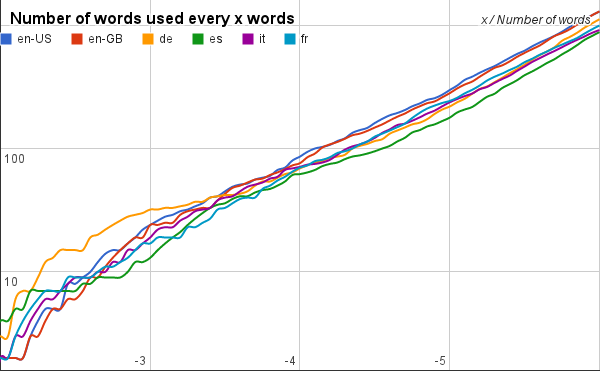
To see which language has the most three-letter words, we just need to see which line is highest around the 4.5-5.0 mark on the graph in the fourth sheet (that you can also see here on the right). The two lines for English (British and American), which are obviously very similar, are always well ahead of neolatin languages (Italian, Spanish and French) [3]. German is ahead at the beginning, meaning that it has more very popular three-letter words, but loses its stamina as it progresses to rarer words, eventually aligning with neolatin languages.
Words usage
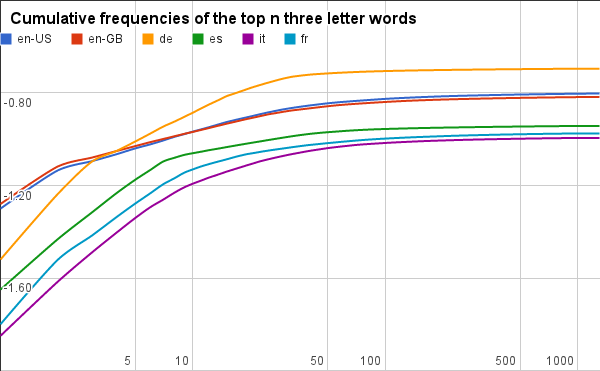
Let us look now at words usage instead, that is, which proportion of words in actual books are three-letter words. The answer is in the graph in the fifth sheet and again copied here on the left.
Because of the strong start highlighted in the previous section, German leads: when you speak German, one in five word has three letters! English is around the 15% mark, and neolatin languages are just around 10-11%. It is interesting that the proportion of the top five German three-letter words (der, die, und, von, den) is more or less the same of the proportion of all Italian three-letter words.
The original question
The question we started from was a different one, though: if it looks like a word, is it a word? I collected some preliminary results on which percentage of trigrams are actual words in the considered languages in the third sheet (and in the last corresponding graph).
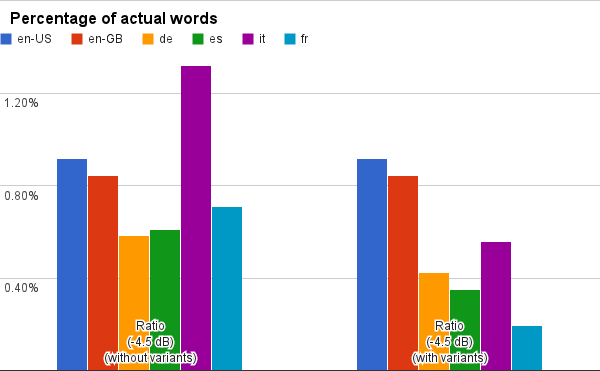
The answer really depends on what we consider a letter: English is easy, 26 letters, but other languages are more complicated. Italian as spoken and written nowadays, for example, has 21 “base” letters, and 7 additional letters with diacritics: à, è, é, ì, ò, ó, ù: of these, only two have actual phonetic meaning (i.e., there is a phonetic difference between grave and acute accent), the others just mark the stressed syllable when it is the final one. Just a hundred year ago Italian had at least one base letter more (j) and some more diacritics variation. So, how many trigrams are there in Italian, 21 to the third, or 28 to the third? I think that the correct answer is the first, but not really sure, so I left both versions in the sheet.
Anyway, comparing the used words with all possible trigrams, it turns out that the language with the highest percentage of real words is… Italian! Not considering letter variants, Italian wins with 1.32%, over English with 0.9%. If we instead consider letter variants as different letters, then English wins with, no wonder, still 0.9% over Italian with 0.56%.
This is really a rough approximation of the original question, as definitely not all trigrams look like words! As this post is already too long, I will try to answer to our original question, by counting how many trigrams look like a word, in a future post.
Part of this series
- If it looks like a words, then it is a word (?)
- If it looks like a word, it is a word one third of the time
-
I am not talking about accents here, these are different dialects. ↩
-
Admittedly, you will sound weird anyway, as you will invariably make mistakes in different directions and your sentence will be a mix of different dialects. ↩
-
In particular because also the y axis is logarithmic, so at -4.5 Italian has only three-quarter of American English three-letter words, and Spanish just 60%. ↩